- mysql三层架构
- mysql server层结构
- 索引的作用
- 索引缺点
- 一张表最多能建多少个列和索引
- 一级索引和二级索引
- 索引是存储在内存还是磁盘的
- 有或者无索引的情况下是怎么查找数据的?
- 查询比较慢,一般卡在哪?
- 去磁盘读取数据的时候,是用多少读取多少吗?
- 很重要的概念:局部性原理
- 索引为什么能加快查询
- 索引是怎么存储的?
- 为什么用B+树来存储索引?
- 在mysql中有没有hash索引
- 存储引擎的分类
- 树的分类
- 聚簇索引和 非聚簇索引 的区别
- innodb中,如果id是主键,后面我把name字段添加为索引,这棵树是怎么样存储的?
- innodb插入数据时必须要包含一个索引的key值
- 什么是存储引擎
- mysql会自动创建索引嘛
- 为什么只能有一个聚簇索引
- myisam和innodb区别
- 数据存储在哪个目录
- 索引监控
mysql三层架构
+--------------+| 客户端 |+--------------+↓+--------------+| 服务端 |+--------------+↓+--------------+| 存储引擎 |+--------------+
mysql server层结构
当客户端需要查询一条sql时,在server端内部走了以下4步
+--------------+| 连接器 |+--------------+↓+--------------+| 分析器 |+--------------+↓+--------------+| 优化器 |+--------------+↓+--------------+| 执行器 |+--------------+
索引的作用
- 加快数据的访问
- 将随机io变成顺序io
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 减少io次数,提高磁盘寿命
索引缺点
加了索引之后查询会更快,但是当数据量大的时候,增删改就会变慢;因为每次修改数据时除了数据本身,数据库还需要维护索引的那颗B+树;
一张表最多能建多少个列和索引
- innoDB: 最多创建1017列, 最多64个二级索引,加上主键有65个, 单个索引最多包含16列, 索引最大长度767字节(其实行格式为REDUNDANT,COMPACT最高为767字节,但行格式为DYNAMIC,COMPRESSED最高可达为3072字节), 行大小最大65536字节
- mysiam: 最多4096列, 最多64个二级索引, 单个索引最多包含16列, 索引最大长度1000字节, 行大小最大65536字节
一级索引和二级索引
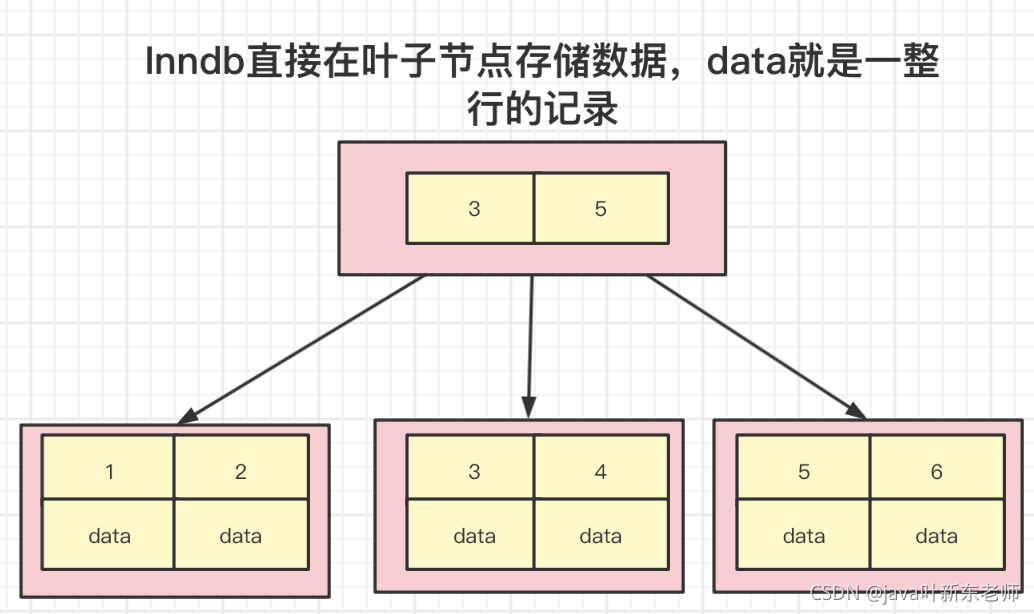
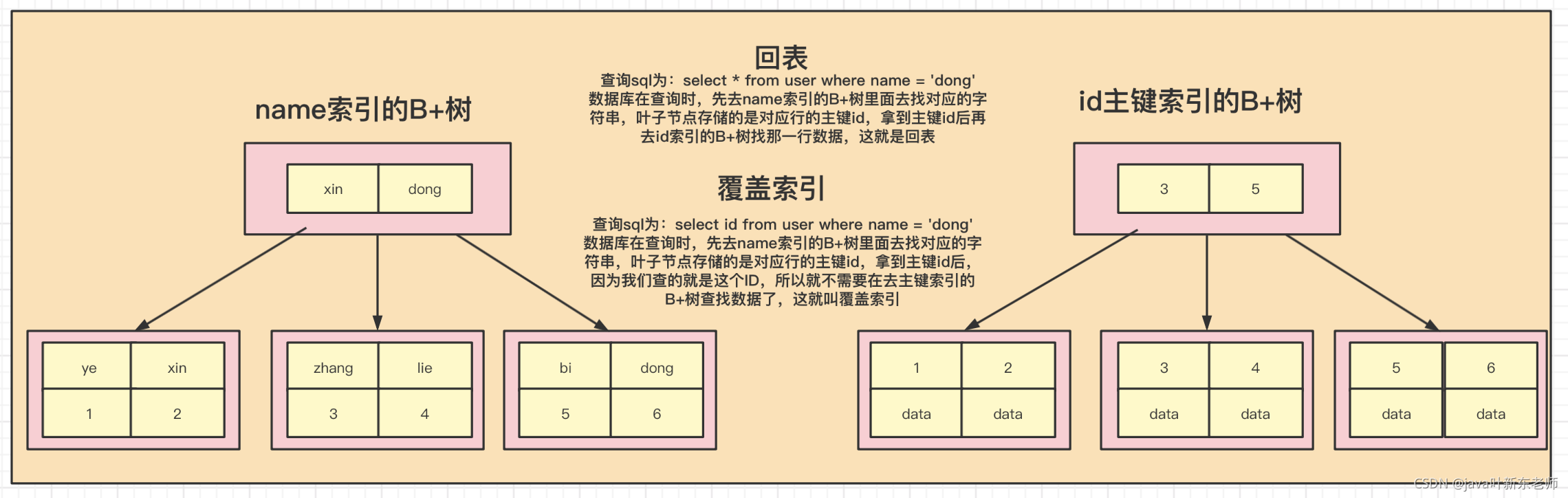
- 一级索引:索引和数据存储在一起,都存储在同一个B+tree中的叶子节点。一般主键索引都是一级索引。主键就是聚簇索引,一个表就一个主键,一个表也就一个聚簇索引,所以综上所述,主键 = 一级索引 = 聚簇索引
- 二级索引:二级索引树的叶子节点存储的是主键而不是数据。也就是说,在找到索引后,得到对应的主键,再回到一级索引中找主键对应的数据记录。在innodb中,所有的二级索引B+树都指向一级索引的key值,所以查询二级索引时需要回表才能查到一整行数据;
索引是存储在内存还是磁盘的
索引都是存储在磁盘里面的,因为需要持久化存储,内存里也有,但都是每次查询时从磁盘加载到内存里的
有或者无索引的情况下是怎么查找数据的?
无索引:没有索引的情况下,都会全表扫描,就是一条条地找,这无疑效率不高,又费io;
有索引:有索引的情况下,会为这个索引生成一颗B+树,有了这颗树的帮助,查询数据的效率会提升几千倍;
查询比较慢,一般卡在哪?
- 卡在io上,就是input和output,
- 解决方案是提高io效率,
- 减少io的次数,
- 减少io的量:尽可能地查询减少查询的数据,尽量避免用select * from xxx
去磁盘读取数据的时候,是用多少读取多少吗?
肯定不是啦,mysql和磁盘交互的时候是以页为单位进行传输的,默认情况下,每页大小为16K,,就像我们在电脑上新建一个txt文件,里面什么内容都没有,但它还是占用了4KB,mysql也一样,有自己的最小页大小,可通过 innodb_page_size 参数观看数据页大小
mysql> show variables like 'innodb_page_size';+------------------+-------+| Variable_name | Value |+------------------+-------+| innodb_page_size | 16384 |+------------------+-------+
很重要的概念:局部性原理
- 数据和程序都有狙击成群的倾向,同时之前被访问过的数据很可能再次被查询,空间局部性、时间局部性
- 磁盘预读
- 内存跟磁盘交互时,一般情况下有一个最小的逻辑单元,称之为页(datapage),页的大小由系统决定,一般是4k或8k,并且一定是整数倍的,4、8、16、32、64、128….. 数据交互时,可以去页的整数倍来进行读取,innodb存储引擎,每次读取数据都是16k
索引为什么能加快查询
要解决这个问题,我们就得先知道索引是怎么存储的
索引是怎么存储的?
一个索引对应一个B+树,如果一张表建了10个索引,那就会有10个B+树,
OLAP联机分析处理—-数据仓库—hive
对海量历史数据进行分析,产生决策性的影响
OLTP联机事务处理—关系型数据库
要求在很短的时效内返回对用的数据
为什么用B+树来存储索引?
hash索引不适合用来做数据库的结构,
- 如果是单个等值值查询(通过key查找value),那么就会非常快,
- 不支持范围查询,进行范围查询时,必须要挨个遍历
- 对内存的要求比较高,
- 哈希冲突会造成数据散列不均匀,会产生大量的线性查询,很浪费时间
在mysql中有没有hash索引
答:有
- memory存储引擎使用的是hash索引
- innodb支持自适应hash,就是由mysql来决定使用hash还是树来存储,人工无法干预
存储引擎的分类
- innodb :持久化 + 内存
- memory :只存储在内存,不支持持久化,断电就没了,结构是hash表
- myisam :持久化
可以在建表是自己指定存储引擎,就像这样
MySQL5.5版本之前,默认内置存储引擎是Myisam,create table (id bigint(20) primary key ,name varchar(10)) engine='innodb';
MySQL5.5版本之后,MySQL的默认内置存储引擎已经是InnoDB,
树的分类
- 二叉树
- BST树(binary search tree)必须保证顺序
- AVL树 平衡二叉树,有序
- 红黑树
- B树
- B+树
- 在很早很早很早很早以前,索引是用用二叉树实现的,大概是2点几版本的
- 二叉树本身是无序的,所以发展出了有序的BST树,BST在插入数据的时候必须保证有序,左子树必须小于根节点,右子树必须大于根节点;
- bst树插入时如果是连续递增或递减顺序的话,就会退化成链表,所以衍生出了会旋转的平衡二叉树avl,
- avl树插入慢,查询快,因为插入的时候为了保证平衡,需要进行旋转操作,平衡二叉树有一个条件,为了保证平衡,最短子树和最长子树的长度差不能超过1,所以会经常要旋转,旋转也是需要性能开销的。所以平衡二叉树只能用于插入少、查询多的数据,当我们的查询和插入一样多 情况下,使用平衡二叉树就不合适了,所以这时候又衍生出了一种新的数据结构:红黑树
- 红黑树最长子树只要不超过最短子树的2倍即可,但是随着数据的插入,发现树的深度会变深,树的深度越深,意味着io次数越多,就会影响数据读取的效率;所以为了解决这个问题,就需要把有序的二叉树,变成有序的多叉树,这就是B树
- B树中每层都存储数据,但是每个磁盘块能存储的内容是有限的,除了索引之外,还要存储数据,而数据占用的空间更多,这就使得能存储的索引变少了,如果想要插入更多的数据,就得在加一层,变成四层,但是这样会增加io量,所以为了解决这个问题,衍生出了B+树;
- B+树只在叶子节点储存数据,非叶子层只存储索引,并且B+树不但可以从上往下查找,还可以从下往上查找数据;
聚簇索引和 非聚簇索引 的区别
innodb只能有一个聚簇索引,但是有很多的非聚簇索引
- 聚簇索引: 数据和索引是放在一起的,就是聚簇索引,就像这样
+----------+| 索引值 |+----------+| 数据 |+----------+
- 非聚簇索引:数据和索引是分开存放的,在B+树中索引值对应的是文件地址,就是非聚簇索引,可以肯定的是,所有的非聚簇索引都指向了聚簇索引,就像这样
+------------+| 索引值 |+------------+|数据文件地址|+------------+
innodb中,如果id是主键,后面我把name字段添加为索引,这棵树是怎么样存储的?
一开始我的主键是id字段,那么在B+树中叶子节点的结构是这样的
+----------+|主键索引值|+----------+| 数据 |+----------+
这时候我又把name字段设置为索引了,这时候mysql为这个name索引也创建一颗B+树,这颗树的叶子节点存的就不是数据了,如果存数据的话会造成冗余,所以这个name索引树存的是主键id,就像这样
+----------+| ye |+----------+/ \+----------+ +----------+| xin | | dong |+----------+ +----------+| 主键id | | 主键id |+----------+ +----------+
innodb插入数据时必须要包含一个索引的key值
向innodb插入数据的时候,必须要包含一个索引的key值,这个索引的key值,可以是主键,如果没有主键,就是唯一键,如果没有唯一键,那么就是一个自生成的6字节的rowid;
- myisam用的都是非聚簇索引;
- innodb只有一个聚簇索引,有多个非聚簇索引;
什么是存储引擎
索引的创建跟存储引擎是挂钩的,存储引擎表示不同的数据在磁盘存储的文件格式也是不同的。
mysql常用的存储引擎有三个
- memory :内存级别的存储引擎,不支持持久化,断电丢失数据,hash索引
- myisam : mysql 5.5之前默认的存储引擎,每次修改数据都会锁表,不支持事务
- innodb : mysql 5.5之后默认的存储引擎,支持事务、行锁;
mysql会自动创建索引嘛
innodb只能有一个聚簇索引,但是有很多的非聚簇索引,向innodb插入数据的时候,必须要包含一个索引的key值,这个索引的key值,可以使主见,如果没有主键,就是唯一键,如果没有唯一键,那么就是一个自生成的6字节的rowid;
为什么只能有一个聚簇索引
因为主键只有一个,聚簇索引对应的就是主键字段,只有主键的索引B+树才会存储数据,其他的二级索引存储的都是主键的值;
如果每个二级索引树都存储数据的话,就会造成数据的冗余;
myisam和innodb区别
- myisam支持表锁,innodb支持表锁和行锁
- myisam不支持外键,innodb支持外键
- myisam不支持事务,innodb支持事务
- 在计算机内存足够的情况下,innodb效率比myisam高,因为innodb是优先读缓存, myisam是直接从磁盘读取数据
数据存储在哪个目录
数据存储在: 你的mysql目录/data/db1/ 目录下,
其中,
- 后缀为.opt的文件是一个配置文件,指定该数据库的字符集编码
- 后缀为.frm的文件就是表结构
- 后缀为.idb表示当前表用的存储引擎是innodb
- 后缀为.myd是数据文件。使用的存储引擎是myisam
- 后缀为.myi是索引文件,使用的存储引擎是myisam
索引监控
查询语句为:show status like ‘Handler_read%’;
结果说明:
Handler_read_first 代表读取索引头的次数,如果这个值很高,说明全索引扫描很多。
Handler_read_key:代表一个索引被使用的次数,如果我们新增加一个索引,然后通过这个索引来查询数据,,可以查看Handler_read_key是否有增加,如果有增加,说明sql用到索引。这个数量越大越好,大表示索引查询使用的比较多;
Handler_read_next:代表读取索引的下列,按(主)键顺序依次读取之后的N行
Handler_read_last : 从(主)键的最后位置开始读取
Handler_read_prev: 代表读取索引的上列,一般发生在ORDER BY … DESC。
Handler_read_rnd: 代表在固定位置读取行,如果这个值很高,说明对大量结果集进行了排序、进行了全表扫描、关联查询没有用到合适的KEY。
Handler_read_rnd_next: 代表进行了很多表扫描,查询性能低下。
关于mysql 的mysql 回表、索引覆盖、最左匹配、索引下推,请看我的另一篇文章 :添加链接描述


