为了搞懂HashMap,作者经常夜不能寐,熬夜刷文章、看源码、撸代码、做测试,终于在今天下午的1点30分55秒搞HashMap究竟是何方神圣,我想,这也许就是代码的魅力吧,为了这玩意我可真是煞费苦心,虽然辛苦,但是也很开心,又研究透了一样东西,这种快乐简直让人流连忘返,不多说,开始表演!
HashMap在各JDK 版本的区别
- 在JDK1.7以前,HashMap 是用 【数组 + 单向链表】 实现的,
- 而在JDK 1.8 是使用 【数组 + 单向链表 + 红黑树】实现的,
本文主要具体讲讲数组+单向链表的实现,有些童鞋会说了:“既然已经使用了红黑树了,为啥不直接讲红黑树结构呢?”,首先,这是好问题,让我们先把掌声给到这位提问的童鞋(台下掌声雷动);其次,我想说的是:“万丈高楼平地起,你想建造高楼大厦,必须先把地基打好,而数组 + 单向链表就相当于是我们的地基,并且jdk1.8最开始也是数组+单向链表的结构,只不过当链表长度大于 8 或者 数组长度大于 64 时才会转为数组 + 红黑树结果,而且红黑树也是基于链表发展而来的一种二叉树结构,它的机构相对来说会比较复杂,如果一上来就直接讲红黑树,可能童鞋们一时间消化不了,而作者我本人也会被指着鼻子骂,说我写的东西不清不楚,这些,都不是我想要的,俗话说,授人以鱼不如授人以渔,如果看完这篇文章对你有所启发,那我也就功德圆满了”;扯远了哈,圆规正转;
单向链表
有些童鞋也许会云里雾里的,所以想想有必要解释下什么叫单向链表,其实单向链表非常简单,就是一个元素中除了元素本身之外,还存储一个指针,这个指针指向下一个元素,像我们JAVA里面常用来遍历Set用的 Iterator 迭代器就是一个典型的 单向链表;
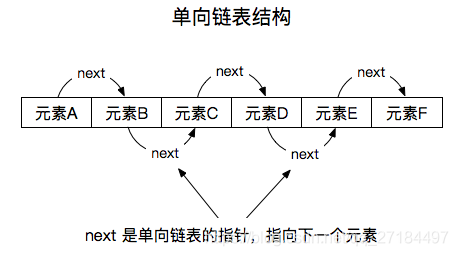
数组 + 单向链表的结构
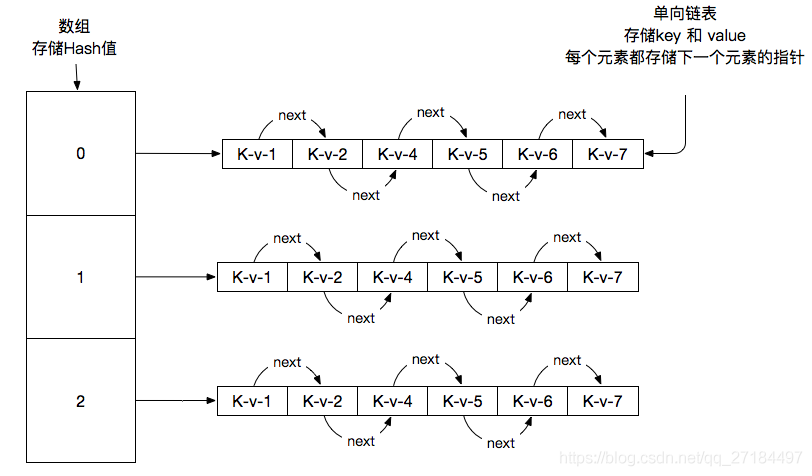
HashMap是怎么存储数据的?
调用put()方法后,先拿到key值的hashCode;去计算出哈希值,也就是数组的下标位置,计算Hash值的代码如下,此处代码我做了简化,运行的结果和hashMap的结果一致,源代码要远比我这个复杂的多,简化的目的是为了让童鞋们通俗易懂;了解底层的计算方式;
- /**
- * 计算hash值
- * @param key
- * @return 返回的index就是要存放到数组的下标
- */
- static final int hash(Object key) {
- int default_init_size = 16; // map容量,默认16
- int h = key.hashCode();
- // 大名鼎鼎的扰动函数,先将hashCode右位移16位 ,在和HashCode异或运算 , >>> 表示无符号右移
- int hash = h ^ (h >>> 16);
- // 关键代码,计算Hash值
- int index = (default_init_size - 1) & hash;
- return index;
- }
存储数据的流程图如下
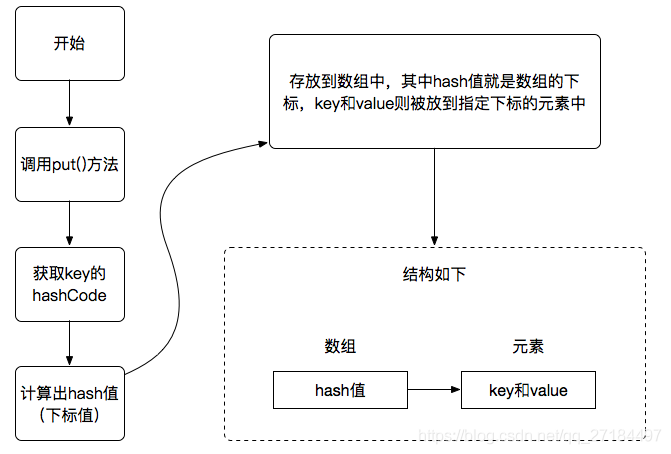
扩容机制
为什么要扩容?
- 因为链表越长,查询效率越低
- 节点(元素)越多会影响效率
- 扩容可以减少hash冲突
要了解扩容机制,就必须先了解2各东西,分别是 初始容量 和 负载因子
- 初始容量:int类型,值为 16,这个16 就是数组的长度,源码用 1 << 4 表示16;
- 负载因子:,是一个 float 类型,值为 0.75,另外多说一句:负载因子越小,hash冲突就越少;
扩容条件和扩容后的数量
扩容就必须用到这2样东西,首先,HashMap 扩容的时候,不是满了才去扩容的,是到了一定基数的时候就扩容了,相当于提前扩容,那么提前多久呢,这时候就要用到 负载因子 了,当 HashMap内的 数组长度 > (负载因子 * 初始容量) 时,就会触发扩容机制,比如 初始容量是16,那么就可以得出公式 :16 * 0.75 = 12 ,由此公式我们可以知道, 当数组的容量大于 12 的时候,就会触发扩容机制了,而且每次扩容都会扩大一倍,初始容量是16,扩容后就是 32
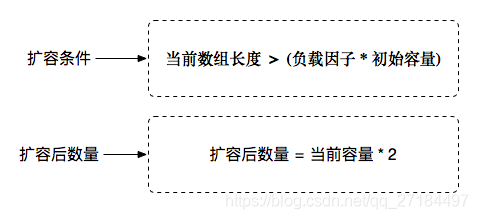
因为扩容后长度会发生变化,所以扩容后会重新计算hash值!
如何解决hash冲突?
我们先明白一个概念: hash == 数组下标,所以当我讲数组下标的时候其实就是hash值,当我讲到hash值的时候其实就是数组下标,因为如果单纯的说hash,很多人不知道是什么玩意,说下标会更容易理解;
既然要解决,我们就得知道什么是hash冲突,说白了,其实就是数组的下标冲突了,比如 “K100” 和 “K111” 这2个key通过计算得出的hash值都是 4,因为我们只有一个数组,也就只有一个下标,那么4这个下标到底给谁用呢? 给 “K100” 还是 “K111” 用呢?这就叫做hash冲突!
怎么解决呢?
这时候我们的链表就起到作用了,在存储的时候,其实是这2个key 都共用一个下标,至于谁先谁后,那就要看是谁先put进去的;先添加的会排在后面,所以,加进去后的结构是这样的
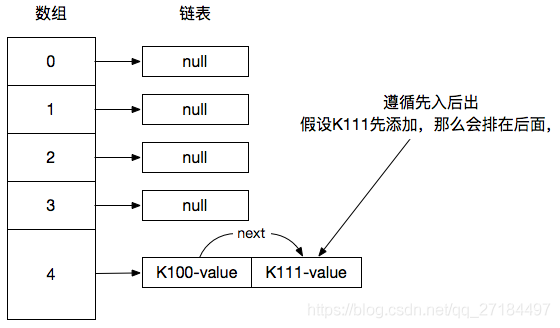
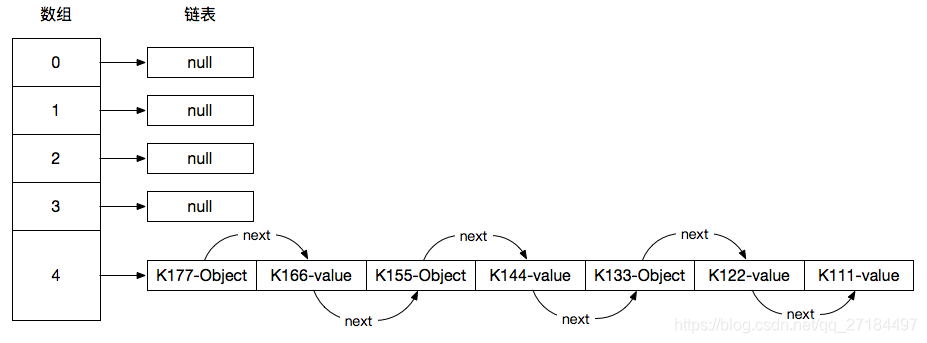
假设有以下代码,可以确定的是,它们的hash值都是4,就是说,通过put()方法加入hashMap集合后,它们都在下标为4的链表中,
- public static void main(String[] args) {
-
- Map<String,Object> map = new HashMap<>();
- // 以下的key值,已经通过计算,它们的hash值都是4,
- map.put("K111", new Object());
- map.put("K122", new Object());
- map.put("K133", new Object());
- map.put("K144", new Object());
- map.put("K155", new Object());
- map.put("K166", new Object());
- map.put("K177", new Object());
-
- System.out.println(map);
- }
执行上面的代码后,HashMap的结构是这样的
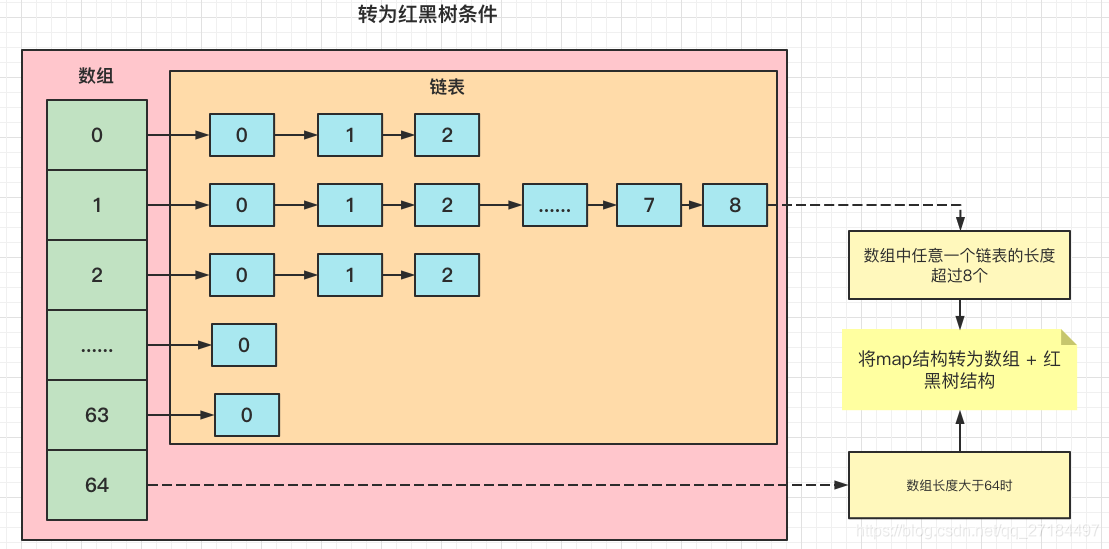
JDK1.8 中数组+链表 转为数组+红黑树的条件
在JDK1.8之后,HashMap中的链表在满足以下两个条件时,将会转化为红黑树(即自平衡的排序二叉树):
1. 条件一:数组 arr[i] 处存放的链表长度大于8
2. 条件二:数组长度大于64。
HashMap 完结
HashMap 到这里就介绍完了,你有没有看明白呢? 如果有错误,欢迎指出,欢迎探讨交流;
LinkedHashMap
LinkedHashMap 和 HashMap最大的差别就是 LinkedHashMap 是有序的,所以在底层结构中又加了一个双向链表,比起HashMap,LinkedHashMap消耗的资源相对会比较多一些;而且LinkedHashMap不是线程安全的,
看到LinkedHashMap 的源码我们发现LinkedHashMap 其实就是继承了HashMap,所以 LinkedHashMap 的结构就是 HashMap + 双向链表,不知道双向链表的话可以看我的另一个关于集合的文章: https://blog.csdn.net/qq_27184497/article/details/115394591?spm=1001.2014.3001.5501 在这里不做过多赘述;
只要搞懂了HashMap就可以很容易搞懂LinkedHashMap。
HashTable
HashTable 和 HashMap 大致是一样的,但是还有些小区别,大致区别如下
- HashTable 是线程安全的,每个方法都带有 synchronized 的关键字,而HashMap 是线程不安全的
- HashTable 不允许存储null值和null键,HashMap 允许 null值和null键
- 扩容机制不同,HashTable初始大小为11,并且每次扩容都为:2 * 当前容量 + 1。HashMap的默认大小为16,并且一 定是2的指数,每次扩容都为 当前容量 * 2。
HashSet
通过查看HashSet的源码可以看到,HashSet 的底层其实就是用 HashMap 来存储数据的,因为HashMap 的key 不能重复,所以HashSet 添加相同的元素也会覆盖掉,我们在看看构造方法,当我们实例化一个HashSet的时候,在底层又实例化了一个HashMap;
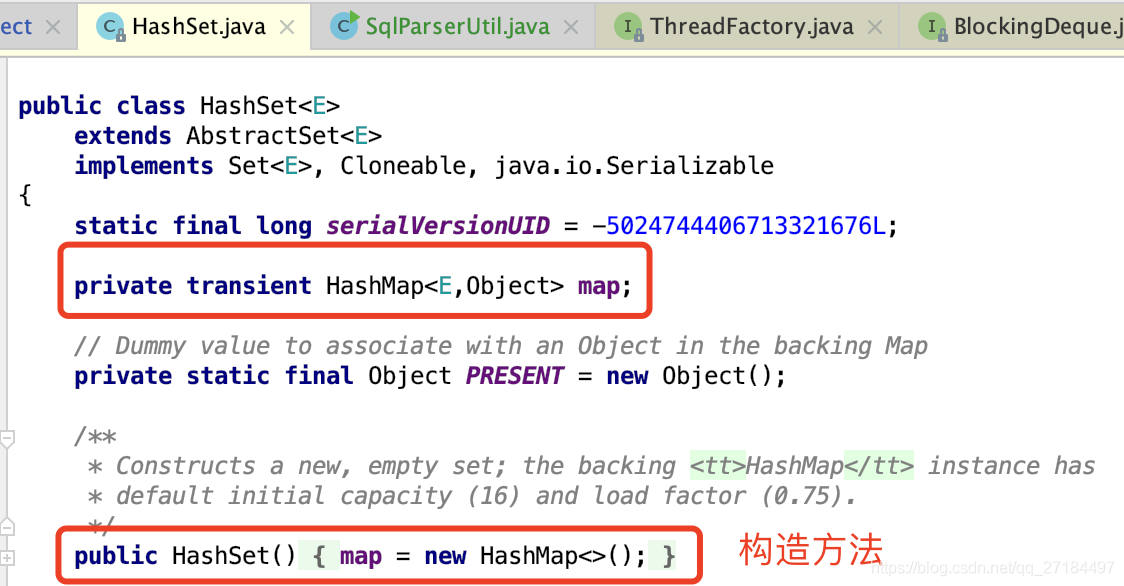
我们看看HashSet 的 add() 方法, 调用方法后,将元素放入了 HashMap 的 key 中,而元素是 PRESENT ,在最上面可以看到,PRESENT 就是一个Object ;
- // Dummy value to associate with an Object in the backing Map
- private static final Object PRESENT = new Object();
-
- public boolean add(E e) {
- return map.put(e, PRESENT)==null;
- }
面试可能会问到的问题
-
hashMap 的初始容量为什么是16?
-
为了提高性能,如果初始容量太小,元素增加会触发多次扩容,每次扩容都会重建哈希表,这是很耗费性能的,初始容量太大会造成冗余的情况;
-
-
hashMap扩容为什么是2的幂次?
-
为了减少hash 冲突; 太大了也会造成冗余的情况
-
-
HashMap 的负载因子为为什么是 0.75
-
当负载因子为1.0时,意味着只有当hashMap装满之后才会进行扩容,虽然空间利用率有大的提升,但是这就会导致大量的hash冲突,使得查询效率变低。
-
当负载因子为0.5或者更低的时候,hash冲突降低,查询效率提高,但是由于负载因子太低,导致原来只需要1M的空间存储信息,现在用了2M的空间。最终结果就是空间利用率太低,
-
负载因子为0.75时解决了以上2个问题,即避免了大量的hash冲突,又提升了查询效率
-


