awk命令说明
与sed一样,均是一行一行的读取,处理
sed作用于一整行的处理,而awk将一行分成数个字段来处理
字段:一段字符串 —> 一段很多字符组成了一个字符串
1、过滤ps -ef命令,只打印第1,2列,过滤掉其他的列
先看看原始数据
[root@master ~]# ps -efUID PID PPID C STIME TTY TIME CMDroot 1 0 0 2021 ? 01:14:16 /usr/lib/systemd/systemd --switched-root --system --deseriaroot 2 0 0 2021 ? 00:00:00 [kthreadd]root 4 2 0 2021 ? 00:00:00 [kworker/0:0H]root 6 2 0 2021 ? 00:21:46 [ksoftirqd/0]
通过空格进行分割,若有多个空格,awk都会视为是一个空格
# awk默认分隔符为空白,所以以下2个命令的结果是一样的ps -ef|awk -F' ' '{print $1,$2}'ps -ef|awk '{print $1,$2}'
执行结果
[root@master ~]# ps -ef|awk -F' ' '{print $1,$2}'UID PIDroot 1root 2root 4root 6
2、awk其他用法
先看看原始数据
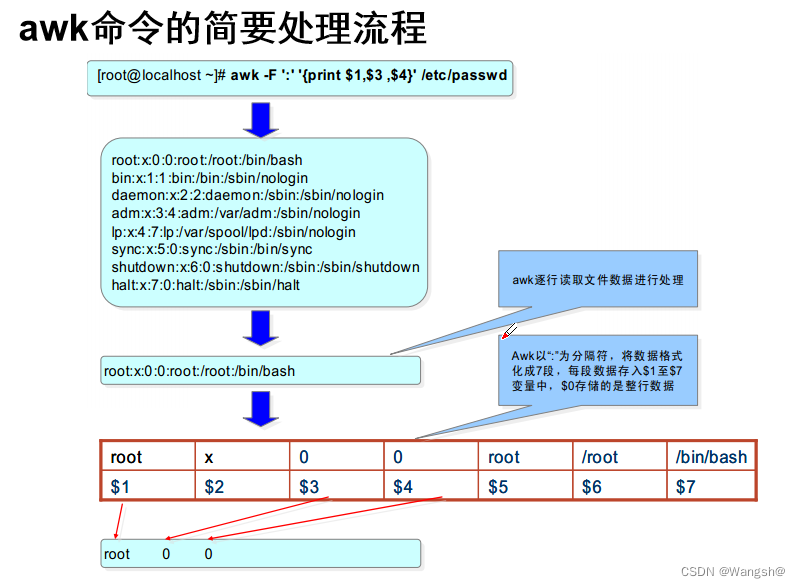
[root@master ~]# cat /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinsync:x:5:0:sync:/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltmail:x:8:12:mail:/var/spool/mail:/sbin/nologinoperator:x:11:0:operator:/root:/sbin/nologingames:x:12:100:games:/usr/games:/sbin/nologinftp:x:14:50:FTP User:/var/ftp:/sbin/nologinnobody:x:99:99:Nobody:/:/sbin/nologinsystemd-network:x:192:192:systemd Network Management:/:/sbin/nologindbus:x:81:81:System message bus:/:/sbin/nologinpolkitd:x:999:998:User for polkitd:/:/sbin/nologinsshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologinpostfix:x:89:89::/var/spool/postfix:/sbin/nologinchrony:x:998:996::/var/lib/chrony:/sbin/nologinnscd:x:28:28:NSCD Daemon:/:/sbin/nologintcpdump:x:72:72::/:/sbin/nologin
2.1、通过 : 进行分割,只打印前三列,过滤掉其他的列过滤前
# 以下2个命令的运行结果是一样的cat /etc/passwd | awk -F: '{print $1,$2,$3}'awk -F: '{print $1,$2,$3}' /etc/passwd
运行后
[root@master ~]# awk -F: '{print $1,$2,$3}' /etc/passwdroot x 0bin x 1daemon x 2adm x 3lp x 4sync x 5shutdown x 6halt x 7mail x 8operator x 11games x 12ftp x 14nobody x 99systemd-network x 192dbus x 81polkitd x 999sshd x 74postfix x 89chrony x 998nscd x 28tcpdump x 72
2.2、过滤第三列大于100的数据
awk -F: '$3>100 {print $1,$2,$3,$4,$5,$6,$7}' /etc/passwd
运行后的结果
[root@master ~]# awk -F: '$3>100 {print $1,$2,$3,$4,$5,$6,$7}' /etc/passwdsystemd-network x 192 192 systemd Network Management / /sbin/nologinpolkitd x 999 998 User for polkitd / /sbin/nologinchrony x 998 996 /var/lib/chrony /sbin/nologin
2.3、输出行号
NR 就是行号
awk -F: '{print NR,$1,$2,$3,$4,$5,$6,$7}' /etc/passwd
2.4、输出1~3行的内容
awk -F: 'NR>=1&&NR<=3 {print $1,$2,$3,$4,$5,$6,$7}' /etc/passwd
2.5、输出第1行和第三行的内容
awk -F: 'NR==1||NR==3 {print $1,$2,$3,$4,$5,$6,$7}' /etc/passwd
2.6、输出奇数和偶数行
# 输出偶数行awk -F: 'NR%2==0 {print $1,$2,$3,$4,$5,$6,$7}' /etc/passwd# 输出奇数行awk -F: 'NR%2==1 {print $1,$2,$3,$4,$5,$6,$7}' /etc/passwd
2.7、print后面什么也不加,输出原内容
[root@master ~]# awk -F: '{print}' /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologin....
2.8、三目运算符
max=($3>$4)?$3:$4三元运算符,如果第3个字段的值大于第4个字段的值,则把第3个字段的值赋给max,否则第4个字段的值赋给max,并输出max的值
awk -F ":" '{max=($3>$4)?$3:$4;{print max}}' /etc/passwd
2.9、输出前5行
awk -F: '{print $1,$2,$3,$4,$5,$6,$7}' /etc/passwd | head -5
2.10、修改输出的分隔符
OFS可以指定输出分隔符
[root@master ~]# awk -F: 'OFS="--" {print NR,$1,$2,$3,$4,$5,$6,$7}' /etc/passwd1--root--x--0--0--root--/root--/bin/bash2--bin--x--1--1--bin--/bin--/sbin/nologin3--daemon--x--2--2--daemon--/sbin--/sbin/nologin4--adm--x--3--4--adm--/var/adm--/sbin/nologin5--lp--x--4--7--lp--/var/spool/lpd--/sbin/nologin......
3、 BEGIN…pattern…END 语法
awk begin完整语法
awk 'BEGIN {commands} pattern {commands} END {commands}' file1
BEGIN: 处理数据前执行的命令,只执行一次END:处理数据后执行的命令,只执行一次pattern:模式,每一行都执行的命令,上面2.x的例子中没有BEGIN和END语法,所以都是pattern模式
注意:BEGIN和END里的命令只是执行一次,pattern里的命令会匹配每一行去处理;
3.1、每个语法执行多个命令
每个语法中可执行多个命令,用分号;隔开,如:
cat /etc/passwd|awk -F ":" 'BEGIN{print "123";print "456"} {print "789"} END{print "91011";print "121314"}'
结果如下
123456789789.....太多789了,省略掉78978991011121314
3.2、begin命令示例1
cat /etc/passwd|awk -F ":" 'BEGIN{print "###start###"} $3>500&&$3<2000 {print $1,$3}END{print "###end###"}'
以上命令一个做了以下几件事
- 打印
###start### - 过滤每一行的第三列字段的值 500 ~ 2000之间的行
- 输出第一列和第三列
- 打印
###end###
输出结果:
###start###polkitd 999chrony 998###end###
3.3、begin命令示例2 - 打印行数
此命令可以统计命令结果中有多少行
awk -F: 'BEGIN {x=0} {x++};END {print x}' /etc/passwd
统计过程中打印每一行的行号
awk -F: 'BEGIN {x=0} {x++;print x};END {print x}' /etc/passwd
3.4、只处理 BEGIN和END
# 只处理BEGINcat /etc/passwd|awk -F ":" 'BEGIN{print "123";print "456"}'# 只处理ENDcat /etc/passwd|awk -F ":" 'END{print "789";print "910111"}'# 只处理BEGIN 和ENDcat /etc/passwd|awk -F ":" 'BEGIN{print "123";print "456"} END{print "789";print "910111"}'


