1、防止消息丢失
发送方
将ack设为1或者-1/all,可以防止消息丢失;如果要做到99.99999%防止丢失,把ack设为all,把min.insync.replicas设为你的集群分区副本的数量即可;
# 表示要将消息刷入集群环境的2个副本中后,才会返回ack;min.insync.replicas=2
消费方
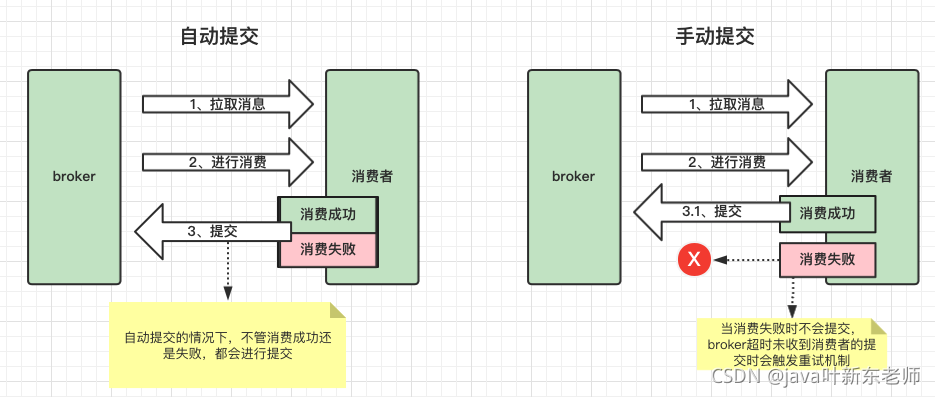
把自动提交改为手动提交,也就是说当我消费成功后才会进行提交。如果设为自动提交的话,那么不管消费者有没有消费成功都会提交给broker,一旦提交上去,offset就会 + 1,表示已经消费成功了,但是消费者这边可能消费失败了;就会造成消息丢失的情况;所以在消费者这边改为手动提交即可;
2、重复消费(幂等性问题)
生产者由于长时间未收到broker的ack,触发了重试机制,导致生产了2条相同的消息,那么在消费的时候就可能会插入2条相同的记录,
以上的问题其实就是幂等性问题,所谓的幂等,就是多访问的结果应该是一样的,对于rest请求来说,除了post是非幂等的之外,get、put、delete都是幂等的;
解决方案如下:
- 关闭重试机制,如果把重试机制关掉的话不显示,虽然解决了重复消费的问题,但是可能会造成丢失消息,(不建议这么做)
- 生产者加id值,数据库在插入数据时将这个id插入数据库,每次消费之前都先查询这个id是否存在,如果已存在就不在消费;
- 加分布式锁;
- 最保险的方式就是将以上2和3的方案一起使用;
3、消息积压
消息积压的原因
消息积压的原因一般情况下都是消息的速度赶不上生产的速度,比如一秒钟的时间里面生产者生产了1000条消息,而消费者在一秒钟里面只消费了500条消息,这种情况下没消费完的消息就会积压在队列里面;
消息积压出现的问题
- 随着消息数据堆积越来越多,消费者寻址的性能越来越慢;最后导致整个kafka对外提供服务的性能很差,从而造成其他服务的访问速度也变慢,最后造成雪崩效应;
- 消息积压还可能会造成的一个问题就是磁盘被堆满,导致生产者的消息数据无法写入磁盘;一直报错,从而引发的连锁反应,也会造成雪崩效应;
消息积压解决方案
- 在消费中使用多线程或线程池一起消费;
- 在业务层面优化代码,提升消费速度
- 创建多个消费组,消费者中创建多个消费者,部署到其他机器上一起消费;提升消费者的消费速度
4、延时队列
使用kafka实现延时队列在功能上稍微费劲点,因为kafka是对于集群高并发下的一种解决方案;像延时队列和顺序消费是它附带的功能,只是并不擅长;
延时使用场景
就像12306app里面买火车票,下单成功后,必须在30分钟内付款,超过30分钟未付款,就将订单取消,这种场景就可以使用延时队列实现;
如何实现延时队列
生产者在发送消息到broker时会有个创建时间,消费者在消费消息时可以通过这个创建时间来判断是否超过 30分钟,如果超过30分钟就代表已过期,如果已过期则将订单取消,消息内容如下
5、顺序消费
因为kafka的消息是根据offset偏移量来消费的,而offset本身就是有有序的,所以在消息本身这一块不需要做任何处理,但是需要在生产者和消费者上做一些功夫;
发送方(生产者)
在发送消息时 ack不能设为0,关闭重试机制,使用同步发送,必须等上一条消息发送成功后才能发送下一条消息,确保消息是顺序发送的;只能发送到一个主题分区中;
接收方(消费者)
确保消息是发送到一个分区中的,并且只能有一个消费者来接收消息
顺序消费产生的问题
因为分区和消费者都只有一个,所以这种按顺序消费的方式会牺牲掉性能;效率不高;所以顺序发送的场景使用的不多;因此kafka也不擅长做这方面的功能;如果非要用kafka,有一种杀鸡焉用牛刀的感觉;


