mq是什么
mq是message queue的简写,也就是消息队列的意思,mq的最终目的就是用来通讯的,有些人会说是用来解耦的,也有人说是用来做应用程序异步的,但其实异步和解耦只是mq的效果,mq的最终目的就是用来通讯的
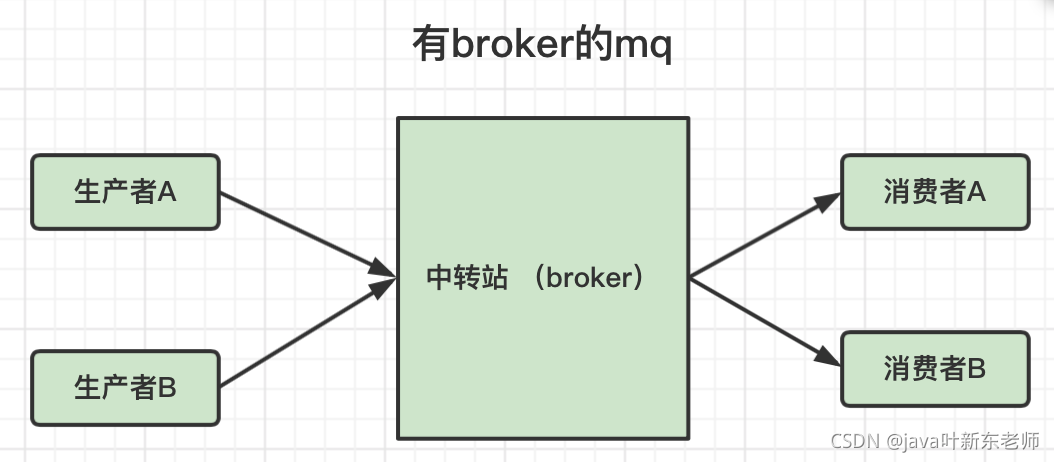
有broker的mq(有中转站)
broker 是什么?可以想象是一个中转站; broker收到生产者的消息后,由broker负责转发到不同的消费者;
+--------+ +--------+ +--------+| 生产者 | -> | broker | -> | 消费者 |+--------+ +--------+ +--------+
有broker的mq又分为重topic和轻topic
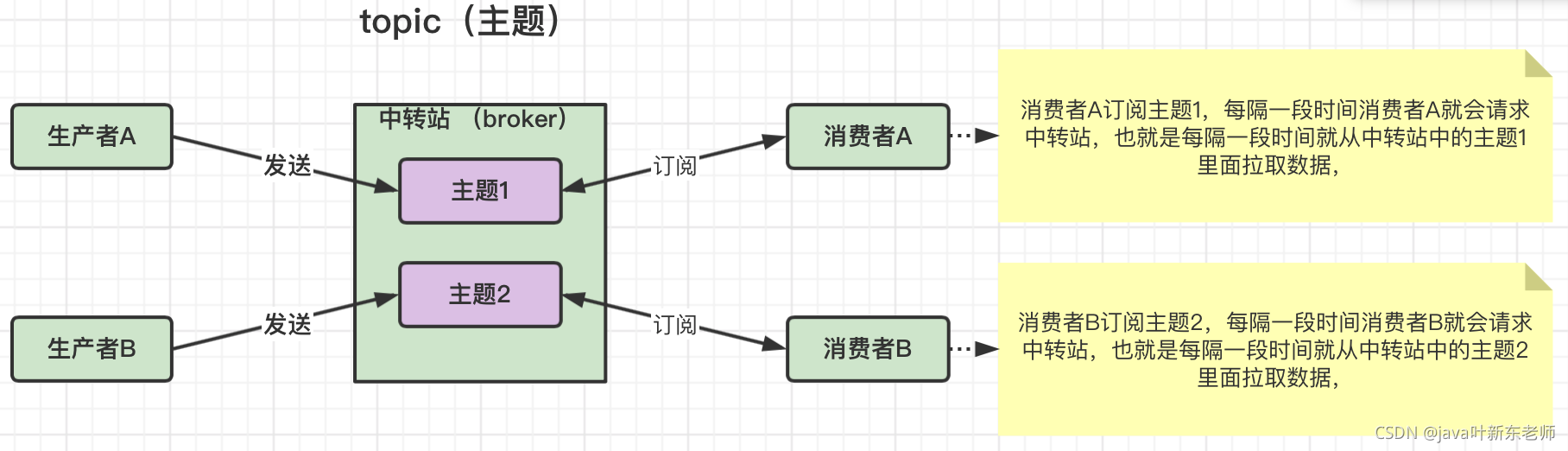
什么是topic
topic可以理解为是主题;一般来说,生产者会有多个,消费者也有多个,那我怎么知道哪个生产者发送的消息是给哪个消费者的呢?所以主题就是用来存储生产者和目标消费者信息的,中转站根据主题信息来决定要发送给哪个消费者
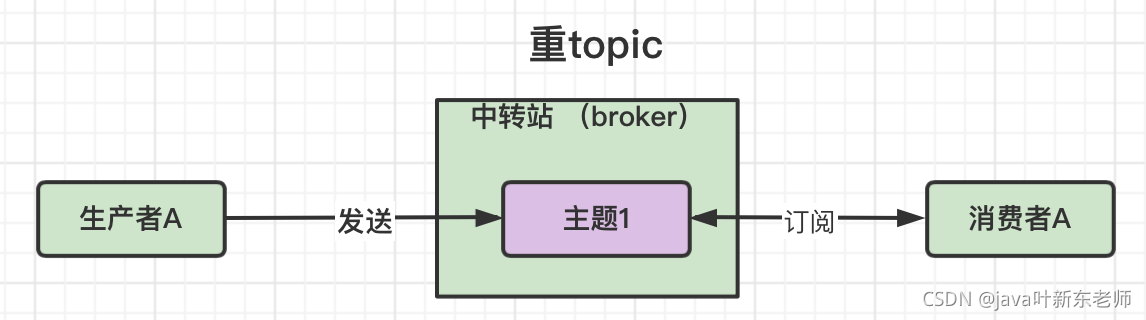
重topic
重topic的意思就是一定有主题topic,比如kafka、rocketMq、activeMq
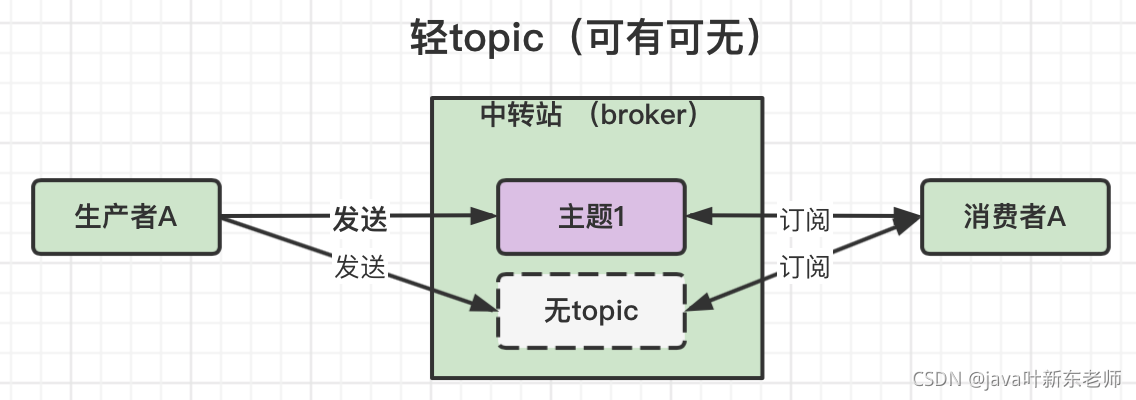
轻topic
不一定要用topic,可以用topic,也可以不用topic,topic只是其中一种中转模式,还有其他的模式可选,rabbitMq就是轻topic;
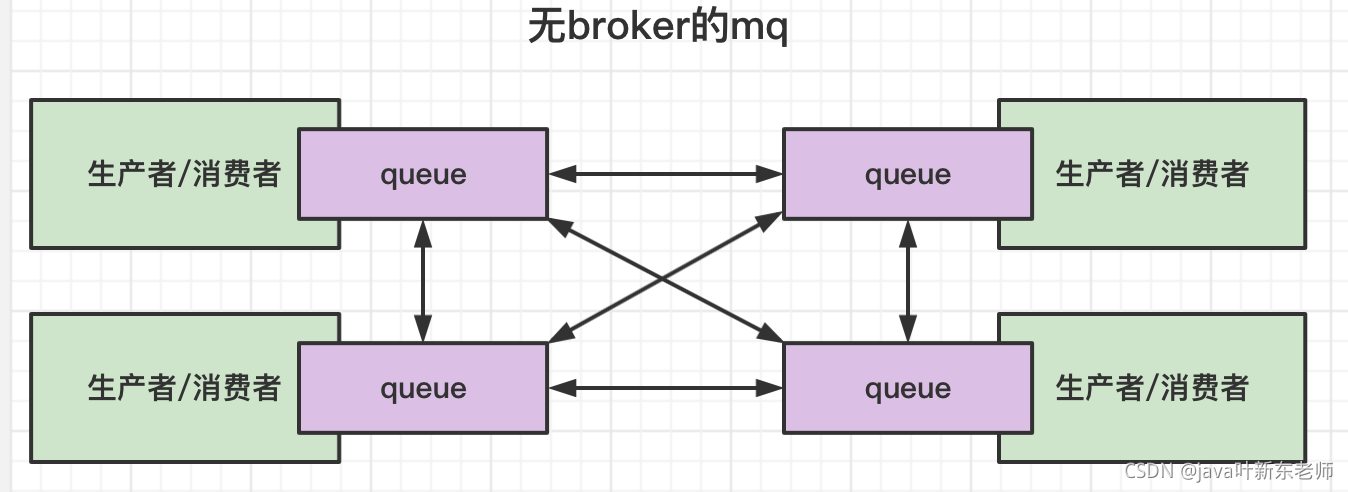
没有broker的mq(没中转站)
zeroMq就是没有中转站的mq,节点和节点之间直接通讯,每个节点都维护了一个消息队列,来接收其他服务发过来的消息,这种mq也可以解决通讯问题,zeroMq的作者认为;mq就是一种更高级别的socket,所以不需要broker也能实现mq的功能;
消息队列的分类
- rabbitMq : 内部可玩性非常强
- rocketMq:阿里内部一个大神,根据kafka的内部执行原理,手写的一个消息队列中间件,性能与kafka相近,功能比kafka多;
- kafka:目前是全球消息处理性能最快的一款mq;
- zeroMq: 无中转站的mq;因为去除了中转过程, 所以处理消息更快;
kafka
目前是全球消息处理性能最快的一款mq;支持分区(partition)、多副本(replica);基于zookeeper协调的分布式消息系统
kafka特点
1、消息保存在日志文件中:
kafka-logs/主题-分区/000000.log // 生产者产生的消息就存储在这个地方kafka-logs/主题-分区/000000.index // 索引文件kafka-logs/主题-分区/000000.timeindex // 时间区间的索引文件
2、 且消息的保存是有序的
3、 消费者消费消息时不会删除消息
4.、消费消息时可通过从头开始消费和从偏移量开始消费2种方式;
消息处理的三种语义
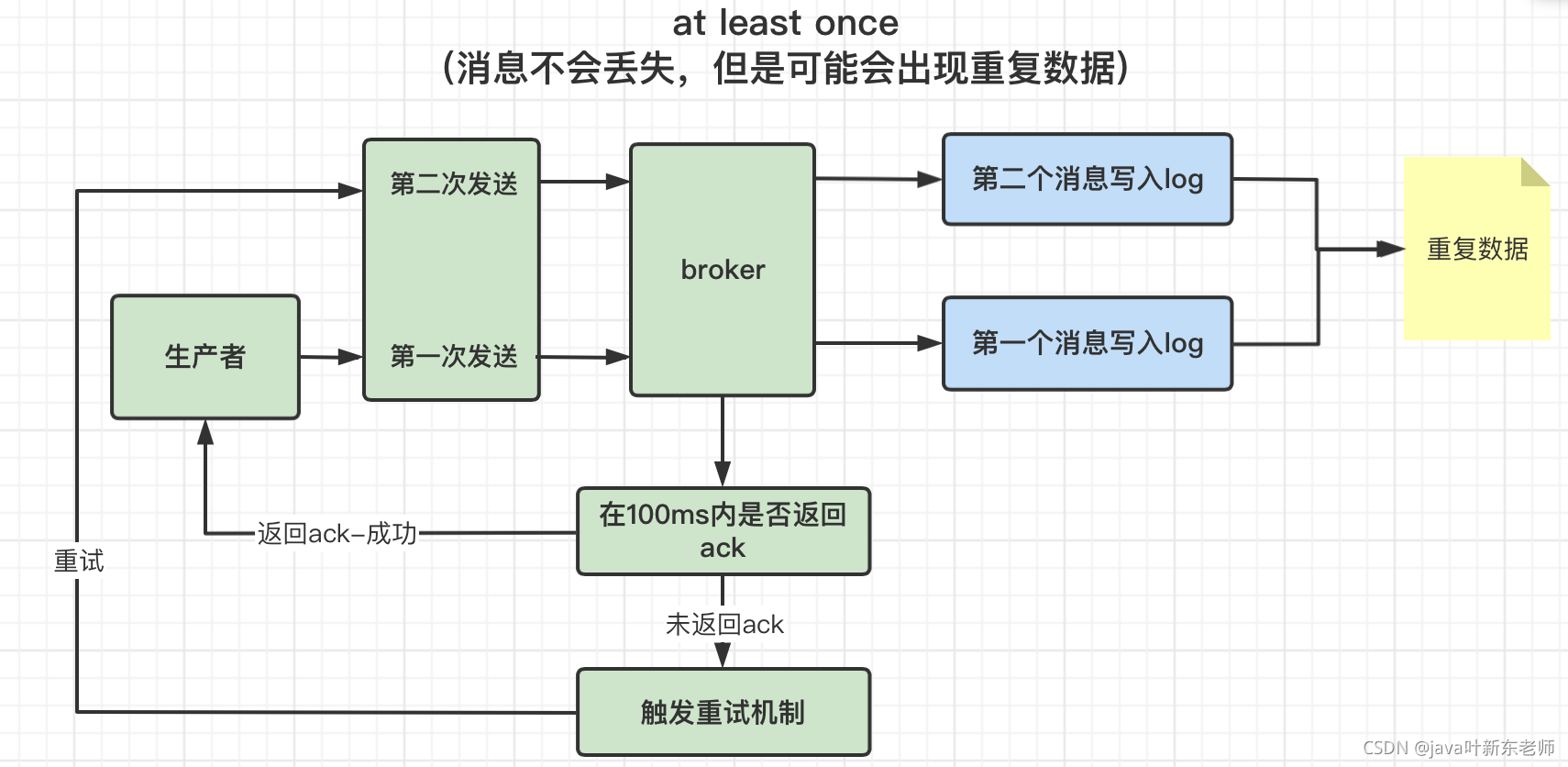
1、at least once
指的是消息不会丢失,但是可能会出现重复数据;
比如生产者发送消息给broker,broker在指定时间内(默认100ms)没返回ack给生产者,但是broker已经将数据写入到了log文件,因为生产者已经超过100ms没收到ack,所以会触发重试机制,在发一次消息到broker;因为刚刚broker已经将数据写到了log文件,这时候又来一个,就会有2个重复的消息,这就是 at least once
2、at most once
指的是消息可能丢失也可能被处理,但最多只被处理一次
3、exactly once
指的是消息被处理且只会被处理一次
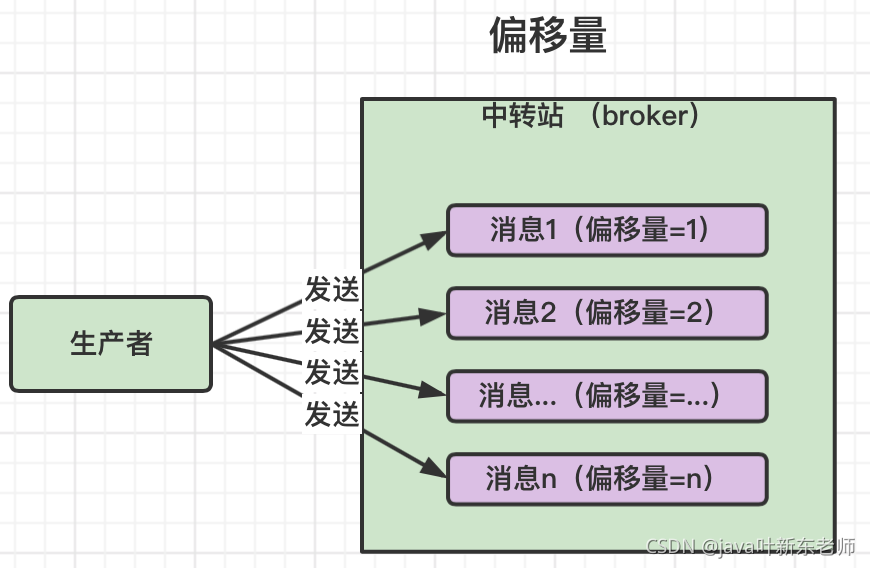
偏移量
在kafka中,偏移量这个概念非常重要,偏移量其实很简单,因为kafka消息是必须保证有序的,所以偏移量就是消费者已经消费到哪一条消息了。生产者发送消息也是按顺序发送,保存到log文件时每次偏移量 + 1;
消费组 comsumer Group
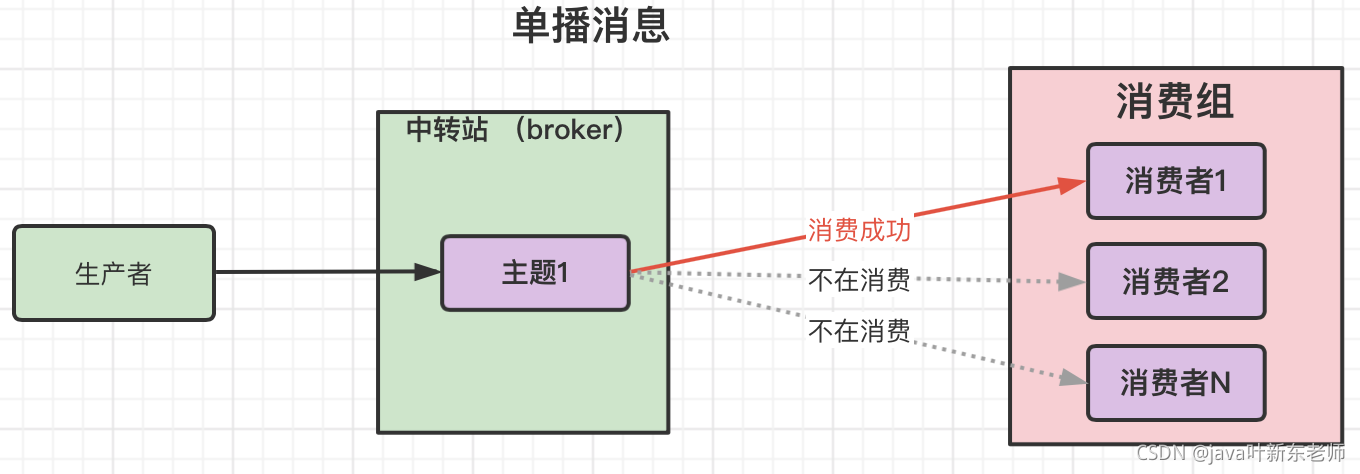
单播消息
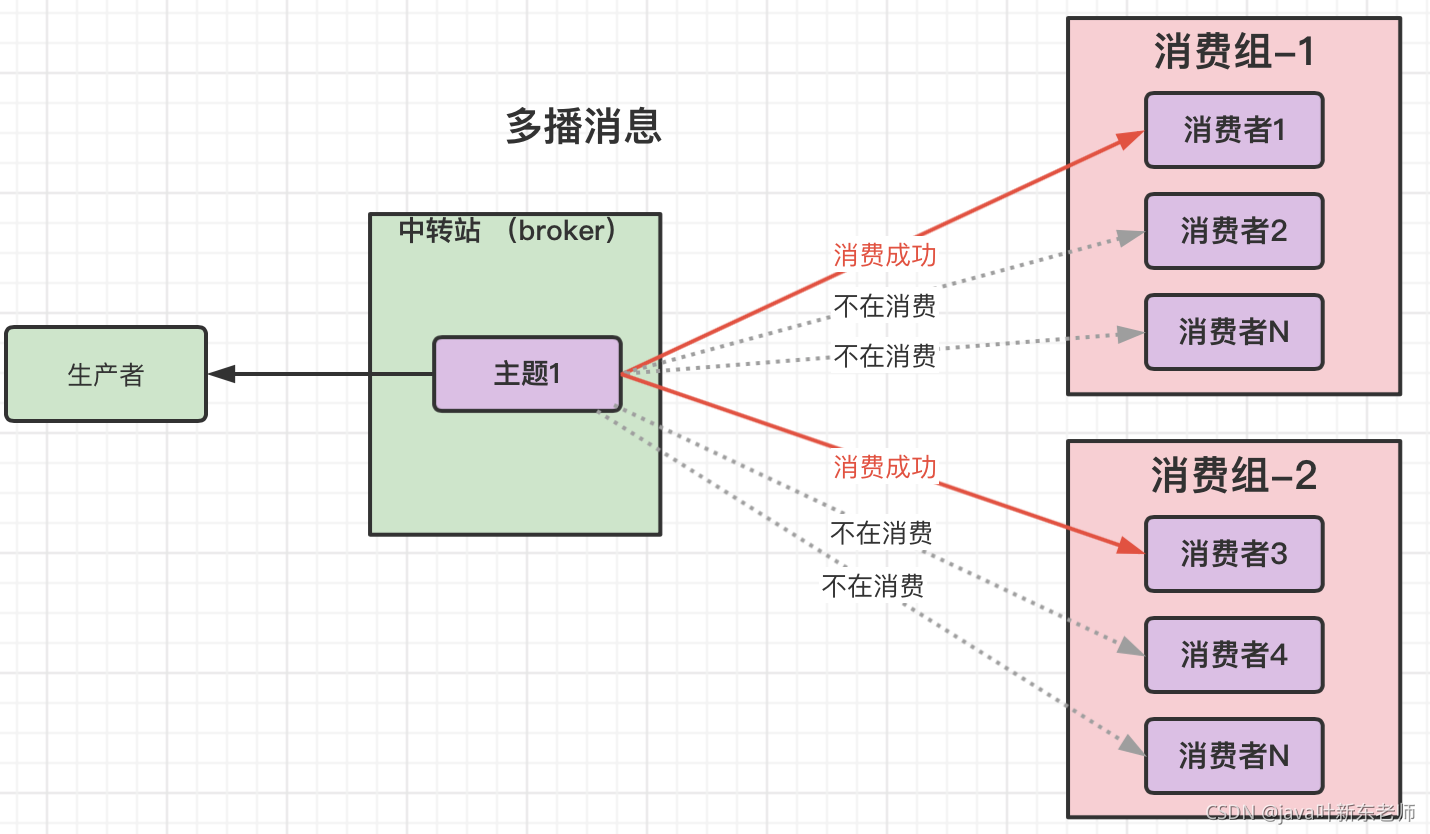
一个消费组下面有多个消费者,消费组中只要有其中一个消费者消费了生产者发送过来的消息,那么组中其他的消费者就不会在重复消费了;
也就是说一个消费组中只能有一个消费者消费成功
多播消息
在单播消息的基础上在增加多个消费组就可以实现多播消息了
消费组信息
查看消费组信息的命令如下
-- 查看某个消费组bin/kafka-consumer-groups.sh --zookeeper 【zk的ip】:2181 --ribe --group testGroup-- 查看所有消费组bin/kafka-consumer-groups.sh --zookeeper 【zk的ip】:2181 --list
| 字段 | 说明 |
|---|---|
| topic | 主题名称 |
| partition | 分区 |
| CURRENT-OFFSET | 当前偏移量(最后被消费的消息偏移量) |
| LOG-END-OFFSET | 消息总量(最后一条消息的偏移量) |
| LAG | 未消费的消息数量(积压了多少消息未被消费) |
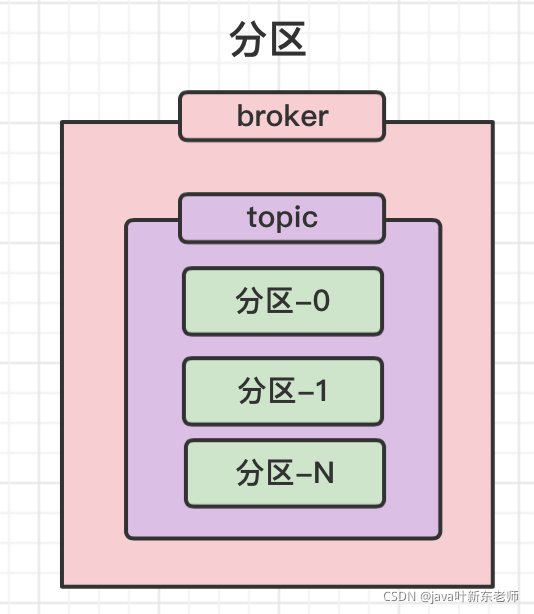
分区 partition
每个topic可配置多个分区,分区是针对文件的 ,如果说你的消息非常多,还有很多消息未被消费,就会存到本地的文件中,像淘宝双11一天都会有几个T的文件,为了解决文件过大的问题,就提出了分区的概念;把一个文件分为几个文件来存储;
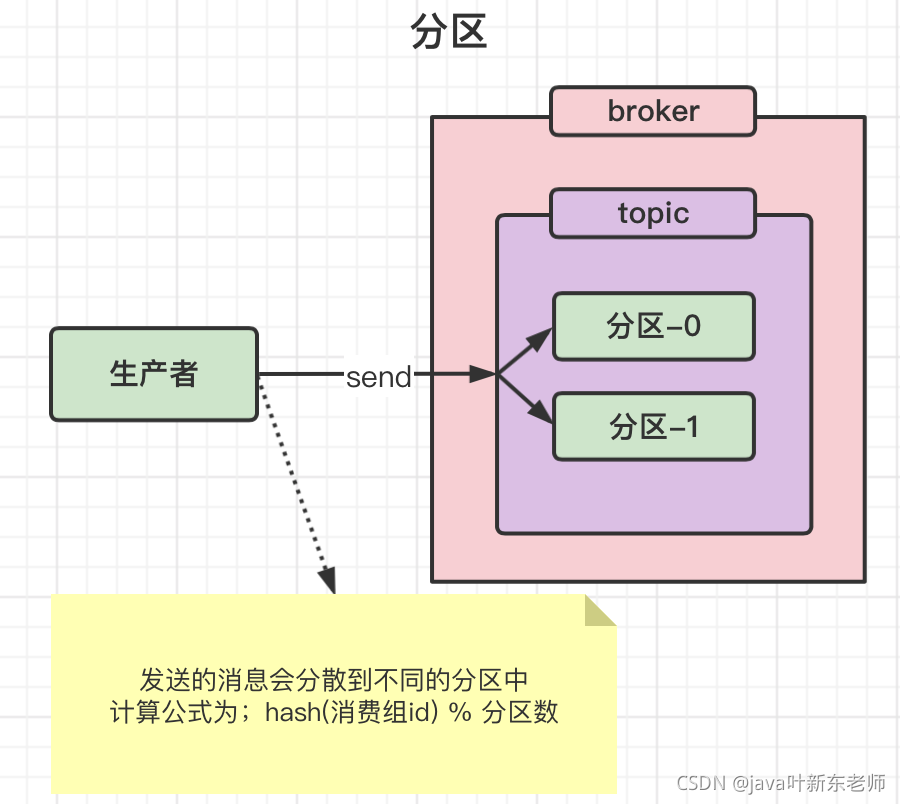
分区如何存储数据
当生产者发送一条消息后,这个消息只会被存储到一个分区下(单节点下的情况,非集群环境),具体存储到哪个分区有一个固定的公式:hash(消费组id) % 分区数 ,乍一看 是不是跟hashMap的计算公式很像? 没错,就是这么简单粗暴的计算公式;
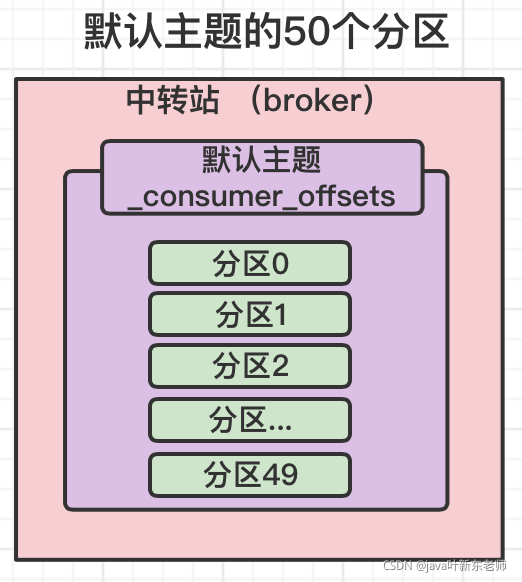
kafks默认主题 _consumer_offsets
kafka内部自己创建了一个叫做_consumer_offsets的主题,包含了50个分区,这个主题用来存放消费者消费每个主题的偏移量;
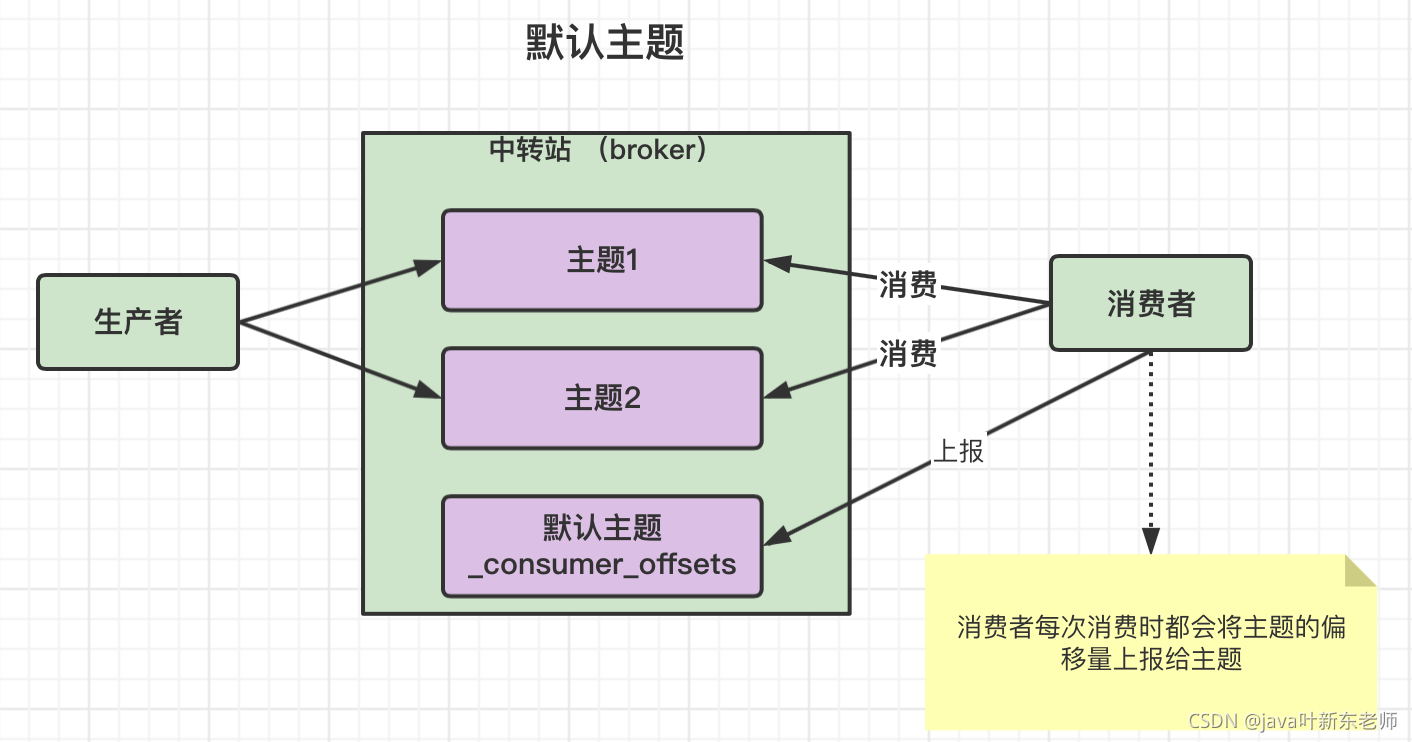
虽然,每个消费者也会自己维护自己消费的偏移量,但是每次消费时,消费者会将消费的主题偏移量上报给kafka的默认主题;
默认主题有50个分区,它提交到哪个分区呢?有个算法,先将消费组进行hash,在对分区树进行取模,公式如下:
hash(consumerGroupId) % 默认主题_consumer_offsets的分区数
_consumer_offsets主题的分区保存时长
默认保存时长为7天,7天后自动删除
副本
简单地讲就是备份,创建的是主题的备份, 也就是主从复制的概念;当主节点挂掉时,从节点可以立马替换主节点的位置;建议有几个集群就创建几个副本,这样一来就可以保证集群环境中每个节点都有一份副本;
现在我们假设一个场景如下
- 创建1个中转站(broker);
- 2个分区(partition);
- 3个副本
那么在kafka中的结构是这样的
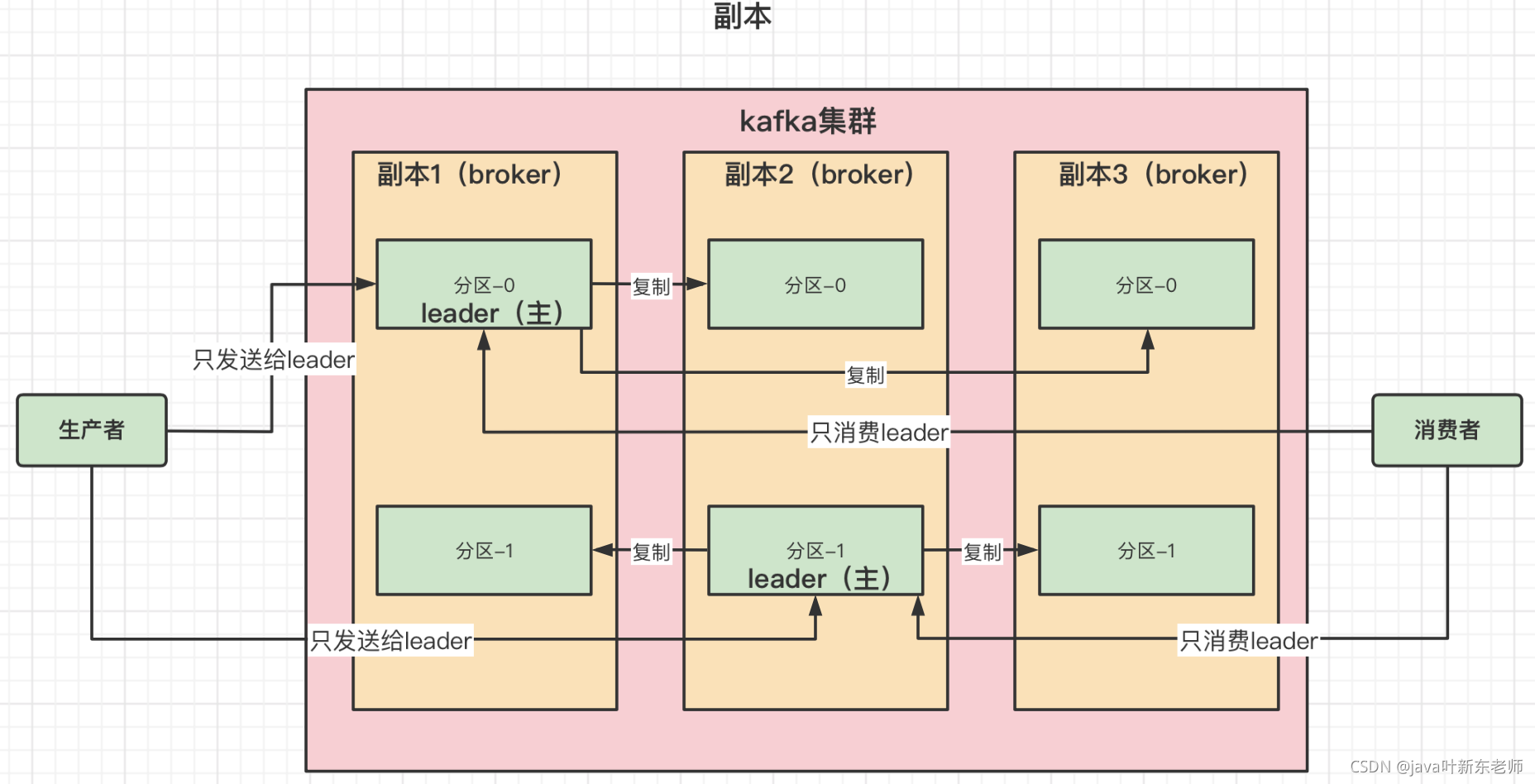
另外,通过上图可以看到,多个副本之间一定有一个leader(主),其他都是备份(从);生产者和消费者只对leader(主)进行通讯,leader(主)接收消息和消费消息后,会将数据复制到备份节点(从);
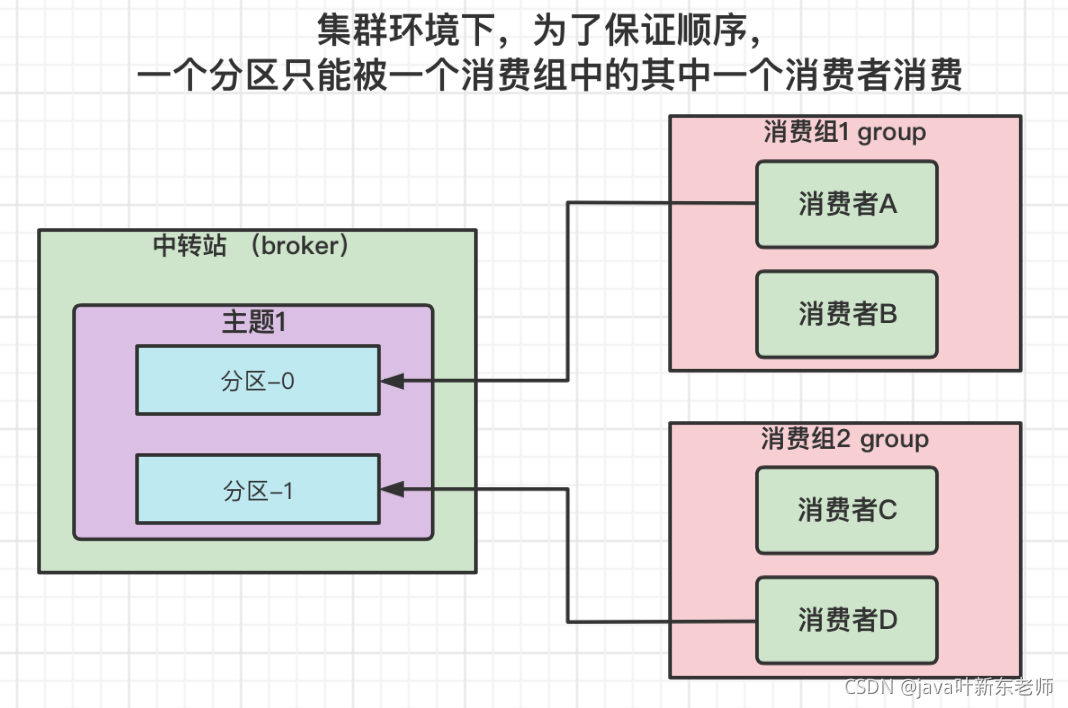
集群消费细节
集群环境下,kafka为了保证消息的顺序,一个分区只能被一个消费者消费;比如分区1被消费者1消费后,其他的消费者就不能消费分区1了
生产者发送消息-同步和异步
- 同步发送: 上一条发送成功后,下一条才能发送,
- 异步发送:直接开多个线程发消息,不需要等待;不管接受者是否接收成功,这种方式容易造成消息丢失;
- 异步回调方式:异步发送消息,以回调的方式告诉发送方是否成功;
同步和异步哪个用的多?产生的问题有哪些
异步发送消息时会产生消息丢失的问题;所以一般都是用同步发消息, 因为异步发消息的话直接就发送消息过去了,你不知道有没有发成功;
但是异步发送消息可以提升速度;关于消息丢失也有解决方案,方案如下:
==在kafka-0.8.2之后,producer不再区分同步(sync)和异步方式(async),所有的请求以异步方式发送,这样提升了客户端效率。producer请求会返回一个应答对象,包括偏移量或者错误信。这种异步方地批量的发送消息到kafka broker节点,因而可以减少server端资源的开销。新的producer和所有的服务器网络通信都是异步地,在ack=-1模式下需要等待所有的replica副本完成复制时,可以大幅减少等待时间。==
kafka消息消费模式
Kafka选取了传统的pull拉取模式;
推送模式 push
由broker主动推送消息给消费者,push的好处:
- broker能以最大速率发送消息;
- 因为有消息就推给消费者,所以延迟小,几乎可以做到实时发送
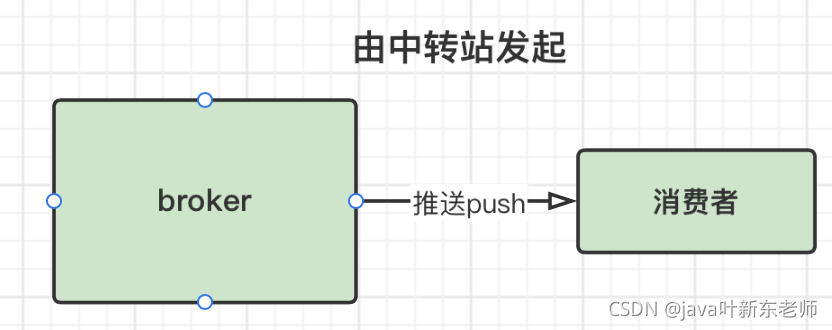
但是这种方式也有2个问题:
- 速率问题,broker推送的速率大于消费者的速率时,消费者可能会崩溃;
- 消费失败,broker推送给消费者的消息,消费者在处理这个消息的时候产生了内部错误,导致这个消息没有消费成功,但是在kafka的broker中已经将这条消息标记为为已发送,但是broker并不知道消费者失败了;所以也没法重新发消息,导致消费失败
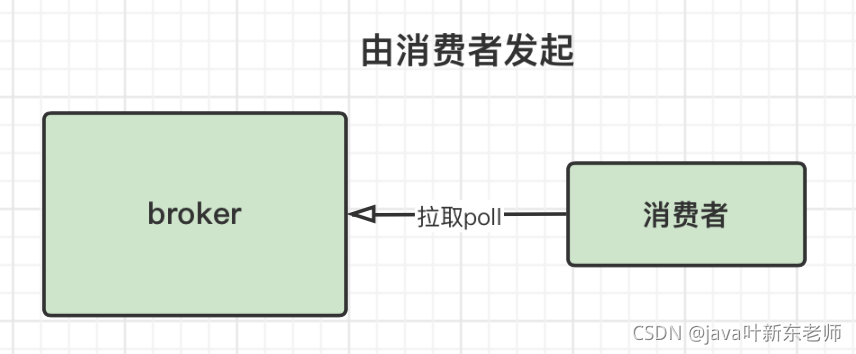
拉取模式 poll
由消费者发起请求去broker拉取消息;好处:
- 可以解决速率问题,因为是由消费者决定何时去拉取消息,所以,不存在速率问题;
- 灵活处理消息,消费失败时,可发送失败的标志位给broker,这样broker就可以知道消费者处理失败了,触发重试机制再发送一次消息给消费者;
poll 拉取模式存在的问题:
- 当broker没有消息推送时,导致消费者不断等待轮询;
- 每个Pull的时间间隔太长,Server端有消息到来有可能没有被及时处理。


